 Home-theater-designers
Home-theater-designers
Som dataanalytiker kommer du ofta att möta behovet av att kombinera flera datamängder. Du måste göra detta för att slutföra din analys och komma fram till en slutsats för ditt företag/intressenter.
Det är ofta utmanande att representera data när den lagras i olika tabeller. Under sådana omständigheter visar joins sitt värde, oavsett vilket programmeringsspråk du arbetar med.
MAKEUSE AV DAGENS VIDEO
Python-kopplingar är som SQL-kopplingar: de kombinerar datamängder genom att matcha deras rader på ett gemensamt index.
Skapa två dataramar för referens
För att följa exemplen i den här guiden kan du skapa två exempel på DataFrames. Använd följande kod för att skapa den första DataFrame, som innehåller ett ID, förnamn och efternamn.
import pandas as pd
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber"]})
print(a)För det första steget, importera pandor bibliotek. Du kan sedan använda en variabel, a , för att lagra resultatet från DataFrame-konstruktorn. Skicka konstruktorn en ordbok som innehåller dina nödvändiga värden.
Slutligen, visa innehållet i DataFrame-värdet med utskriftsfunktionen för att kontrollera att allt ser ut som du förväntar dig.
På samma sätt kan du skapa en annan DataFrame, b , som innehåller ett ID och lönevärden.
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(b)Du kan kontrollera utdata i en konsol eller en IDE. Det bör bekräfta innehållet i dina DataFrames:
Hur skiljer sig Joins från Merge-funktionen i Python?
Panda-biblioteket är ett av huvudbiblioteken du kan använda för att manipulera DataFrames. Eftersom DataFrames innehåller flera datamängder finns olika funktioner tillgängliga i Python för att ansluta dem.
vad står emojierna för
Python erbjuder funktionerna join och merge, bland många andra, som du kan använda för att kombinera DataFrames. Det finns en skarp skillnad mellan dessa två funktioner, som du måste tänka på innan du använder någon av dem.
Join-funktionen sammanfogar två DataFrames baserat på deras indexvärden. De Merge-funktionen kombinerar DataFrames baserat på indexvärdena och kolumnerna.
Vad behöver du veta om Joins i Python?
Innan vi diskuterar vilka typer av anslutningar som är tillgängliga, här är några viktiga saker att notera:
- SQL-kopplingar är en av de mest grundläggande funktionerna och är ganska lika Pythons kopplingar.
- För att gå med i DataFrames kan du använda pandas.DataFrame.join() metod.
- Standardkopplingen utför en vänsterkoppling, medan sammanfogningsfunktionen utför en inre koppling.
Standardsyntaxen för en Python-join är följande:
DataFrame.join(other, on=None, how='left/right/inner/outer', lsuffix='', rsuffix='',
sort=False)Anropa join-metoden på den första DataFrame och skicka den andra DataFrame som dess första parameter, Övrig . De återstående argumenten är:
- på , som namnger ett index att gå med på, om det finns mer än ett.
- hur , som definierar kopplingstypen, inklusive inre, yttre, vänster och höger.
- lsuffix , som definierar den vänstra suffixsträngen för ditt kolumnnamn.
- rsuffix , som definierar den högra suffixsträngen för ditt kolumnnamn.
- sortera , som är ett booleskt värde som indikerar om den resulterande DataFrame ska sorteras.
Lär dig att använda de olika typerna av kopplingar i Python
Python har några gå med alternativ, som du kan utöva, beroende på behovet av timmen. Här är anslutningstyperna:
1. Vänster Gå med
Den vänstra kopplingen behåller den första DataFrames värden intakt samtidigt som den tar in matchande värden från den andra. Till exempel om du vill ta in de matchande värdena från b , kan du definiera det på följande sätt:
c = a.join(b, how="left", lsuffix = "_left", rsuffix = "_right", sort = True)
print(c)När frågan körs innehåller utdata följande kolumnreferenser:
- ID_left
- Fname
- Lname
- ID_right
- Lön
Denna koppling drar de tre första kolumnerna från den första DataFrame och de två sista kolumnerna från den andra DataFrame. Den har använt sig av lsuffix och rsuffix värden för att byta namn på ID-kolumnerna från båda datamängderna, vilket säkerställer att de resulterande fältnamnen är unika.
Utgången är som följer:

2. Högerkoppling
Den högra kopplingen håller den andra DataFrames värden intakt, samtidigt som de matchande värdena från den första tabellen tas in. Till exempel om du vill ta in de matchande värdena från a , kan du definiera det på följande sätt:
c = b.join(a, how="right", lsuffix = "_right", rsuffix = "_left", sort = True)
print(c)Utgången är som följer:
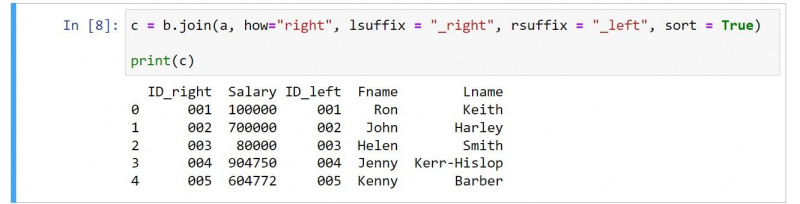
Om du granskar koden finns det några uppenbara ändringar. Till exempel inkluderar resultatet den andra DataFrames kolumner före de från den första DataFrame.
Du bör använda ett värde på höger för hur argument för att ange en rättighetskoppling. Notera också hur du kan byta lsuffix och rsuffix värden som återspeglar den rätta sammanfogningens natur.
I dina vanliga joins kanske du använder vänster, inre och yttre joins oftare jämfört med höger joins. Användningen beror dock helt på dina datakrav.
3. Inre Join
En inre koppling levererar de matchande posterna från båda DataFrames. Eftersom joins använder indexnumren för att matcha rader, returnerar en inre join bara rader som matchar. För den här illustrationen, låt oss använda följande två DataFrames:
wifi säger ansluten men inget internet
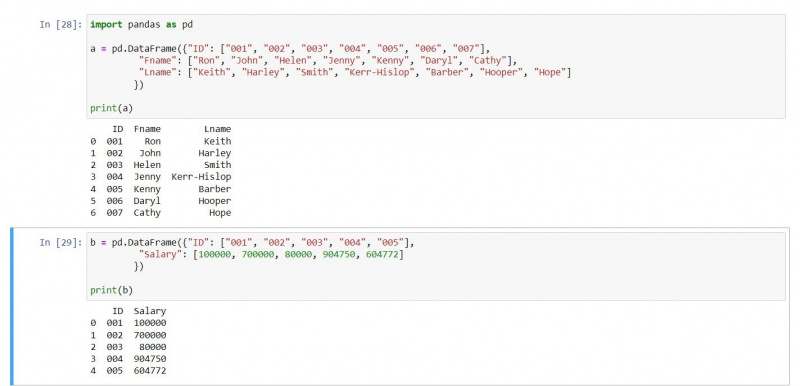
a = pd.DataFrame({"ID": ["001", "002", "003", "004", "005", "006", "007"],
"Fname": ["Ron", "John", "Helen", "Jenny", "Kenny", "Daryl", "Cathy"],
"Lname": ["Keith", "Harley", "Smith", "Kerr-Hislop", "Barber", "Hooper", "Hope"]})
b = pd.DataFrame({"ID": ["001", "002", "003", "004", "005"],
"Salary": [100000, 700000, 80000, 904750, 604772]})
print(a)
print(b)Utgången är som följer:
Du kan använda en inre koppling enligt följande:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='inner')
print(c)Den resulterande utdatan innehåller endast rader som finns i båda indataramarna:
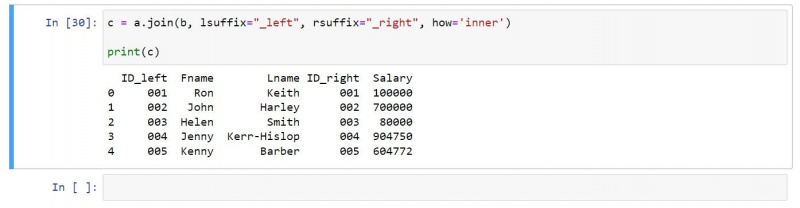
4. Yttre fog
En yttre koppling returnerar alla värden från båda DataFrames. För rader utan matchande värden produceras ett nollvärde på de enskilda cellerna.
Med samma DataFrame som ovan, här är koden för yttre anslutning:
c = a.join(b, lsuffix="_left", rsuffix="_right", how='outer')
print(c)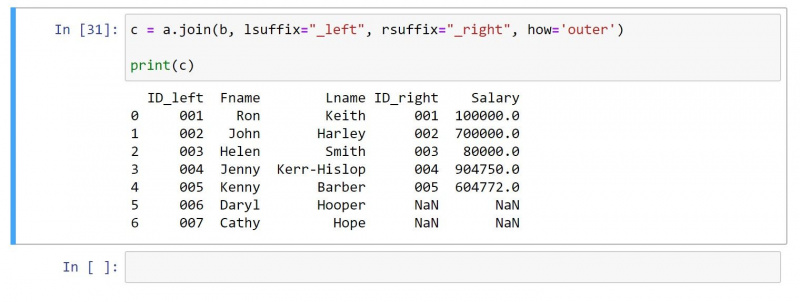
Använda Joins i Python
Joins, liksom deras motsvarighetsfunktioner, sammanfogar och sammanfogar, erbjuder mycket mer än en enkel sammanfogningsfunktion. Med tanke på dess serie av tillval och funktioner kan du välja de alternativ som uppfyller dina krav.
Du kan sortera de resulterande datamängderna relativt enkelt, med eller utan join-funktionen, med de flexibla alternativen som Python erbjuder.